はじめに:なぜYouTube動画のノート化は面倒なのか
私たちは毎日、YouTubeで多くの「学び」を得ています。しかし、その学びを自分の知識ベース(Second Brain)に定着させるのは容易ではありません。
動画を見ながら一時停止し、Obsidianを開き、手動で要約を書く……このプロセスはあまりにも手間がかかります。結果として、「いい動画だったな」という感想だけで終わり、知識として再利用可能な形(Literature Note)に残らないことがほとんどでした。
「ブラウザを経由せず、コマンド一発で、動画から深い洞察を含むノートを作りたい」
この願望を叶えるために、Gemini CLIのカスタムコマンドとPythonスクリプトを組み合わせた自動化パイプラインを構築しました。その結果があまりに素晴らしかったので、技術的な詳細と共に共有します。
システム構成:全体像の可視化
まずは、今回構築したシステムの全体像をご覧ください。
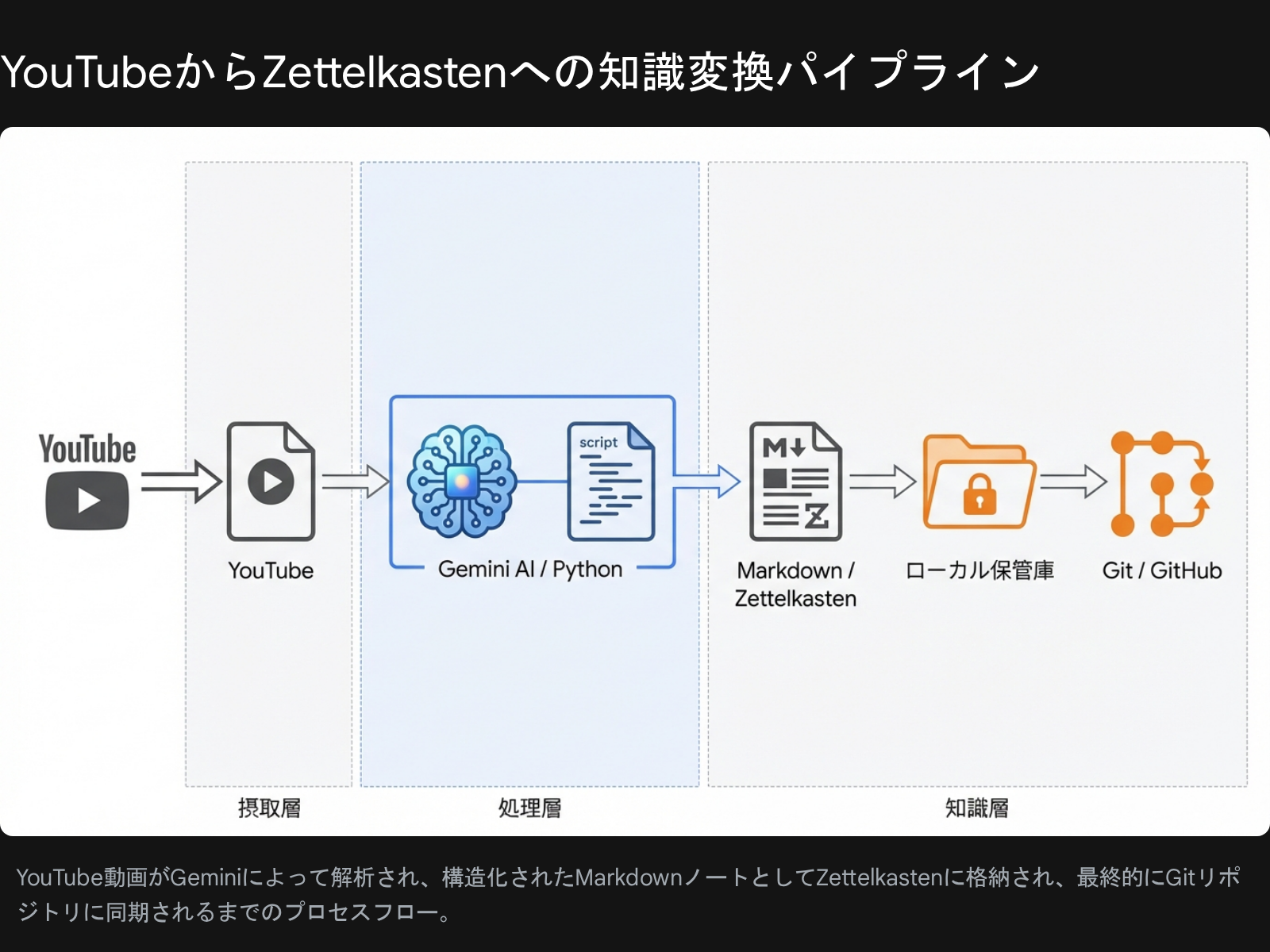
Q: このパイプラインは何を自動化するのか?
A: YouTubeの字幕取得、Gemini 2.0 Flashによる構造化・分析、Markdownファイルへの変換、そしてGitへのコミットまでを、たった1つのコマンドで完結させます。
実装の詳細:3つのステップ
このシステムは、主に以下の3つの要素で構成されています。
1. Pythonスクリプト:頭脳となる処理
中核となるのは
youtube_to_zettel.py
というPythonスクリプトです。このスクリプトは以下の責務を担います。
-
字幕の取得:
youtube-transcript-apiを使用して、指定された動画IDから日本語(または英語)の字幕データを取得します。 -
AIによる分析: 取得したテキストを
google-genaiライブラリ経由で Gemini 2.0 Flash モデルに渡します。ここで重要なのは、「単なる要約」ではなく「概念的な整理」を指示することです。 -
ファイル保存 & Gitコミット:
生成されたMarkdownをZettelkastenの作法(
yyyy/mm/dd/📙タイトル.md)に従って保存し、自動的にgit add&git commitします。
特に、環境変数(.env や
.884162)からAPIキーを柔軟に読み込む設計にすることで、セキュリティと利便性を両立させています。
2. プロンプトエンジニアリング:質の担保
AIが生成するノートの質は、プロンプトで決まります。今回は以下のルールを厳格に適用しました。
単なる「要約」ではなく、動画内で語られた独自の比喩、具体的な数値例、逆説的な理論、重要な洞察を抽出し、知識として再利用可能な形に再構成してください。
これにより、「〜について話しています」というメタな説明ではなく、「なぜそうなるのか」「具体例は何か」という本質的な情報が抽出されます。また、ObsidianのCallout記法(> [!IMPORTANT]など)を積極的に使うよう指示し、可読性を高めています。
3. Gemini CLI カスタムコマンド:起動の簡略化
最後に、これらを呼び出すためのインターフェースです。Gemini
CLIのカスタムコマンド機能(.toml設定ファイル)を利用しました。
# ~/.gemini/commands/dagnetz/literature_from_youtube.toml
description = "YouTube動画からLiteratureノートを作成"
prompt = """
!{python3 ~/dotfiles/shellscripts/zettelkasten_tool/youtube_to_zettel.py "{{args}}"}
"""これにより、ターミナルから以下のように打つだけで、すべてが完了します。
/dagnetz:literature_from_youtube https://www.youtube.com/watch?v=XXXXXX付録:ソースコード
今回作成したスクリプトと設定ファイルの全文です。ご自身の環境に合わせてパスなどを調整してご利用ください。
1. Pythonスクリプト (youtube_to_zettel.py)
以下のコードを ~/dotfiles/shellscripts/zettelkasten_tool/youtube_to_zettel.py として保存してください。
▶ クリックしてコードを表示/非表示
import os
import sys
import datetime
import re
import urllib.parse
import json
import logging
# Ensure dependencies are available or catch import errors
try:
from youtube_transcript_api import YouTubeTranscriptApi
from google import genai
from google.genai import types
from git import Repo
from dotenv import load_dotenv
except ImportError as e:
print(f"Error: Missing dependency {e.name}. Please run: pip install google-genai youtube-transcript-api gitpython python-dotenv")
sys.exit(1)
# Configuration
DOTFILES_DIR = os.path.expanduser("~/dotfiles")
ZETTELKASTEN_DIR = os.path.join(DOTFILES_DIR, "zettelkasten/dagnetz")
ENV_PATH = os.path.join(DOTFILES_DIR, ".env")
RC_PATH = os.path.join(DOTFILES_DIR, ".884162")
# Load Environment Variables
# Try loading from dotfiles root, or rely on system env
# Also try loading from .884162 if it exists
if os.path.exists(ENV_PATH):
load_dotenv(ENV_PATH)
if os.path.exists(RC_PATH):
load_dotenv(RC_PATH)
load_dotenv() # Look in current dir or parents
GEMINI_API_KEY = os.getenv("GEMINI_API_KEY") or os.getenv("GOOGLE_API_KEY")
def extract_video_id(url):
query = urllib.parse.urlparse(url)
if query.hostname == 'youtu.be':
return query.path[1:]
if query.hostname in ('www.youtube.com', 'youtube.com'):
if query.path == '/watch':
p = urllib.parse.parse_qs(query.query)
return p['v'][0]
if query.path[:7] == '/embed/':
return query.path[7:]
if query.path[:3] == '/v/':
return query.path[3:]
return None
def get_transcript_text(video_id):
try:
transcript = YouTubeTranscriptApi.get_transcript(video_id, languages=['ja', 'en'])
formatter = ""
for entry in transcript:
start = int(entry['start'])
minutes, seconds = divmod(start, 60)
timestamp = f"[{minutes:02}:{seconds:02}]"
formatter += f"{timestamp} {entry['text']}\\n"
return formatter
except Exception as e:
print(f"Error fetching transcript: {e}")
return None
def generate_zettel_note(transcript, video_url):
if not GEMINI_API_KEY:
print("Error: GEMINI_API_KEY not found in environment variables or .env file.")
sys.exit(1)
client = genai.Client(api_key=GEMINI_API_KEY)
# Prompt derived from literature.toml and user request
prompt_text = f"""
Video URL: {video_url}
Transcript:
{transcript[:150000]}
Please process the above transcript according to the following rules:
{{args}}の内容を詳細に分析し、Zettelkastenの永続的なノートとして保存するために**概念レベルで深く整理**してください。
単なる「要約」ではなく、動画内で語られた**独自の比喩、具体的な数値例、逆説的な理論、重要な洞察**を抽出し、知識として再利用可能な形に再構成してください。
## 【抽出・分析のルール】
1. **比喩と具体例を詳細に記述**: 話者が用いた独特な比喩(例:「円の面積」「レゴブロック」等)や具体的なエピソードは、その文脈と意図を含めて詳細に書き出してください。ここが最も重要です。
2. **「Why」と「How」の深掘り**: 結論だけでなく、「なぜそう言えるのか(理由)」「具体的にどうするのか(方法)」のロジックを記述してください。
3. **表面的な要約の禁止**: 「~について語っています」というメタな説明は不要です。語られた内容そのものを断定的に記述してください。
4. **概念ごとの構造化**: 時系列(タイムスタンプ順)に縛られず、意味のまとまりやテーマごとに見出しを構成してください。
## 【フォーマットのルール】
- 出力はJSON形式で行ってください。キーは "title" と "content" です。
- "title": ファイル名に使用するタイトル(拡張子なし)。内容は「📙」をプレフィックスにつけた、内容を端的に表すものにしてください。
- "content": ノートの本文。Markdown形式。
- ノートの冒頭に動画URLとタイトルを記載してください。
- インデントを活用し階層構造をはっきりさせる
- ハイフンをたくさん用いて見出しの間を区切る
- 日本語で記述してください。
- **Alert記法(Callout)の積極活用**: 重要な気付き、警告、ヒントは以下の記法を用いて視覚的に強調してください。
> [!NOTE]
> 補足情報や背景知識。
> [!TIP]
> 実践的なアドバイスやコツ。
> [!IMPORTANT]
> 最も重要な概念や核心的なメッセージ。
> [!WARNING]
> 注意点や避けるべき落とし穴。
> [!CAUTION]
> リスクや誤解しやすい点。
"""
try:
response = client.models.generate_content(
model="gemini-2.0-flash",
contents=prompt_text,
config=types.GenerateContentConfig(
response_mime_type="application/json",
response_schema={
"type": "OBJECT",
"properties": {
"title": {"type": "STRING"},
"content": {"type": "STRING"}
}
}
)
)
return response.text
except Exception as e:
print(f"Error generating content with Gemini: {e}")
return None
def main():
if len(sys.argv) < 2:
print("Usage: python3 youtube_to_zettel.py ")
return
video_url = sys.argv[1]
video_id = extract_video_id(video_url)
if not video_id:
print(f"Invalid YouTube URL: {video_url}")
return
# print(f"Processing YouTube Video ID: {video_id}...")
transcript = get_transcript_text(video_id)
if not transcript:
print("Failed to get transcript.")
return
# print("Transcript fetched. Generating note...")
json_result = generate_zettel_note(transcript, video_url)
if not json_result:
return
try:
data = json.loads(json_result)
title = data.get("title", f"📙YouTube-{video_id}")
content = data.get("content", "")
except json.JSONDecodeError:
print("Failed to parse JSON response from Gemini.")
# print(json_result) # Debug
return
# Prepare Save Path
today = datetime.date.today()
save_dir = os.path.join(ZETTELKASTEN_DIR, f"{today.year}/{today.month:02d}/{today.day:02d}")
os.makedirs(save_dir, exist_ok=True)
# Sanitize filename (basic)
safe_title = re.sub(r'[\\\\/*?:"<>|]', "", title).replace(" ", "_")
if not safe_title.startswith("📙"):
safe_title = "📙" + safe_title
filename = f"{safe_title}.md"
file_path = os.path.join(save_dir, filename)
# Ensure content has the URL/Title if LLM missed it, though prompt asked for it.
# We will just write what we got.
with open(file_path, "w", encoding="utf-8") as f:
f.write(content)
print(f"Note saved to: {file_path}")
# Git commit
try:
repo = Repo(DOTFILES_DIR)
repo.index.add([file_path])
repo.index.commit(f"Add Literature note from YouTube: {safe_title}")
print("Committed to Git.")
except Exception as e:
# print(f"Git commit failed (ignoring): {e}")
pass
if __name__ == "__main__":
main()
2. カスタムコマンド設定 (literature_from_youtube.toml)
以下の内容を ~/dotfiles/.gemini/commands/dagnetz/literature_from_youtube.toml として保存してください。
▶ クリックしてコードを表示/非表示
description = "YouTube動画からLiteratureノートを作成"
prompt = """
!{python3 ~/dotfiles/shellscripts/zettelkasten_tool/youtube_to_zettel.py "{{args}}"}
"""得られた成果と感動
この仕組みが稼働した瞬間、本当に感動しました。
- 摩擦ゼロ: 気になる動画を見つけたらURLを投げるだけ。思考を中断しません。
- 高品質なノート: 自分でメモを取るよりも、はるかに構造化され、網羅的なノートが数秒で手に入ります。
- 知識の資産化: Gitにコミットされるため、情報の散逸が防げます。これこそが真の External Memory です。
Q: Zettelkastenとは何か?
A: 知識を「アトミック(最小単位)」なノートとして保存し、それらをリンクさせることで、第二の脳を構築するナレッジ管理手法です。
まとめ:技術で「知」を加速させる
Gemini CLIのような最新のAIツールと、Pythonのようなスクリプト言語、そしてObsidianのようなPKMツールを組み合わせることで、私たちの学習プロセスは劇的に効率化できます。
「面倒くさい」を自動化した先に、本来人間が注力すべき「情報の解釈」や「新しいアイデアの創造」という時間が生まれます。この感動を、ぜひ多くのエンジニアやナレッジワーカーに体験してほしいと思います。
もし興味を持たれた方は、まずは
youtube-transcript-api とGemini
APIを使った単純なスクリプトから始めてみてください。あなたのZettelkastenが、自動的に豊かになっていく様は圧巻です。